트랜스포머 모델과 셀프-어텐션 메커니즘: NLP의 효과적인 해법
현대 사회에서 자연어 처리(NLP, Natural Language Processing) 기술의 중요성은 날이 갈수록 증가하고 있습니다. 인간의 언어를 이해하고, 그를 바탕으로 다양한 작업을 수행하는 기계는 우리의 일상에서부터 전문적인 분야까지 널리 활용되고 있습니다. 그러한 작업 중 하나가 바로 자연어 번역, 챗봇 개발, 감정 분석, 문서 요약 등이며, 이들 모든 작업의 핵심에는 트랜스포머(Transformer) 모델이 자리잡고 있습니다.
트랜스포머 모델은 딥러닝 기반의 NLP 기술을 혁신적으로 발전시킨 핵심 요소입니다. 기존의 순차적인 정보 처리 방식을 넘어서, 문장 내 모든 단어를 동시에 고려함으로써 문맥 이해에 근본적인 변화를 가져왔습니다. 덕분에 더 긴 문장을 더욱 효과적으로 처리할 수 있게 되었으며, 이는 곧 다양한 NLP 작업에서의 성능 향상으로 이어졌습니다.
이러한 트랜스포머 모델의 중요성과 효과를 이해하려면 그 핵심 메커니즘인 '셀프-어텐션(Self-Attention) 메커니즘'을 이해하는 것이 중요합니다. 이 포스트에서는 트랜스포머 모델과 그 핵심인 셀프-어텐션 메커니즘이 무엇인지, 그리고 이를 통해 어떻게 NLP 문제 해결에 기여하는지에 대해 알아보겠습니다.
https://slds-lmu.github.io/seminar_nlp_ss20/attention-and-self-attention-for-nlp.html
Chapter 8 Attention and Self-Attention for NLP | Modern Approaches in Natural Language Processing
In this seminar, we are planning to review modern NLP frameworks starting with a methodology that can be seen as the beginning of modern NLP: Word Embeddings.
slds-lmu.github.io
트랜스포머 모델 개요
트랜스포머 모델은 2017년 구글이 소개한 자연어 처리 기술로, 딥러닝 기반의 자연어 처리 방법론 중 가장 혁신적인 방법 중 하나입니다. 이 모델은 "Attention is All You Need"라는 논문에서 처음 소개되었으며, 이후 여러 NLP 작업에 폭넓게 적용되면서 주목받았습니다.
트랜스포머 모델의 가장 큰 특징은 그 구조에서 볼 수 있는 '셀프-어텐션 메커니즘'입니다. 이 메커니즘을 통해 모델은 입력된 문장에서 각 단어의 중요도를 파악하고, 각 단어 간의 관계를 동시에 고려할 수 있습니다. 즉, 모델은 문장의 각 단어를 독립적으로 보지 않고, 그 문장 전체의 맥락을 고려하게 됩니다.
트랜스포머 모델의 구조는 크게 '인코더(Encoder)'와 '디코더(Decoder)'로 구분됩니다. 인코더는 입력 문장을 벡터 형태의 정보로 변환하고, 이를 디코더가 받아 목표 문장으로 변환합니다. 이때, 인코더와 디코더 모두 여러 층으로 이루어져 있으며, 각 층에서는 셀프-어텐션 메커니즘과 위치 정보를 고려한 연산이 이루어집니다. 이렇게 복잡하게 구성된 트랜스포머 모델이지만, 그 결과는 뛰어난 성능과 깊은 언어 이해력을 보여줍니다.
https://towardsdatascience.com/all-you-need-to-know-about-attention-and-transformers-in-depth-understanding-part-1-552f0b41d021
All you need to know about ‘Attention’ and ‘Transformers’ — In-depth Understanding — Part 1
Attention, Self-Attention, Multi-head Attention, and Transformers
towardsdatascience.com
트랜스포머 모델의 적용
트랜스포머 모델의 성능과 범용성은 다양한 자연어 처리(NLP) 작업에 그 적용을 가능하게 했습니다. 여기서는 몇 가지 주요 작업들을 통해 트랜스포머 모델이 어떻게 사용되는지 살펴보겠습니다.
1. 기계 번역: 기계 번역은 트랜스포머 모델이 처음으로 크게 활용되었던 분야입니다. 트랜스포머 모델의 인코더는 원문을 벡터로 인코딩하고, 디코더는 이 벡터를 대상 언어의 문장으로 디코딩합니다. 이 과정에서 셀프-어텐션 메커니즘을 통해 문장의 각 단어가 다른 단어들과 어떤 관계를 가지는지를 파악하며, 이를 통해 문맥에 맞는 번역을 제공합니다.
2. 챗봇: 챗봇은 사용자의 입력에 적절하게 응답하는 시스템입니다. 트랜스포머 모델은 사용자의 문장을 인코딩하고, 이를 바탕으로 적절한 응답을 생성하는 디코딩 과정을 수행합니다. 이 과정에서 모델은 문장의 각 단어를 독립적으로 처리하는 대신, 전체 문장의 맥락을 고려하여 보다 자연스러운 대화를 생성할 수 있습니다.
3. 감성 분석: 감성 분석은 주어진 텍스트의 감정 또는 성향을 파악하는 작업입니다. 트랜스포머 모델은 텍스트를 인코딩하고, 이 인코딩된 정보를 바탕으로 긍정적인지 부정적인지를 판단합니다. 이러한 판단 과정에서 모델은 문장의 전체적인 맥락을 고려하기 때문에, 단순히 키워드에 의존하는 것보다 정확한 분석이 가능합니다.
4. 요약: 트랜스포머 모델은 주어진 문장이나 문서를 짧게 요약하는 작업에도 사용됩니다. 모델은 문장을 인코딩하고, 이 정보를 바탕으로 요약된 문장을 생성합니다. 여기에서도 셀프-어텐션 메커니즘은 문장의 전체 맥락을 고려하여 중요한 정보만을 추려내는 데 중요한 역할을 합니다.
이렇게 다양한 NLP 작업에서 트랜스포머 모델은 그 성능을 입증하였습니다. 그러나 이 모델의 성능을 이끌어내는 핵심 요소는 바로 셀프-어텐션 메커니즘입니다.
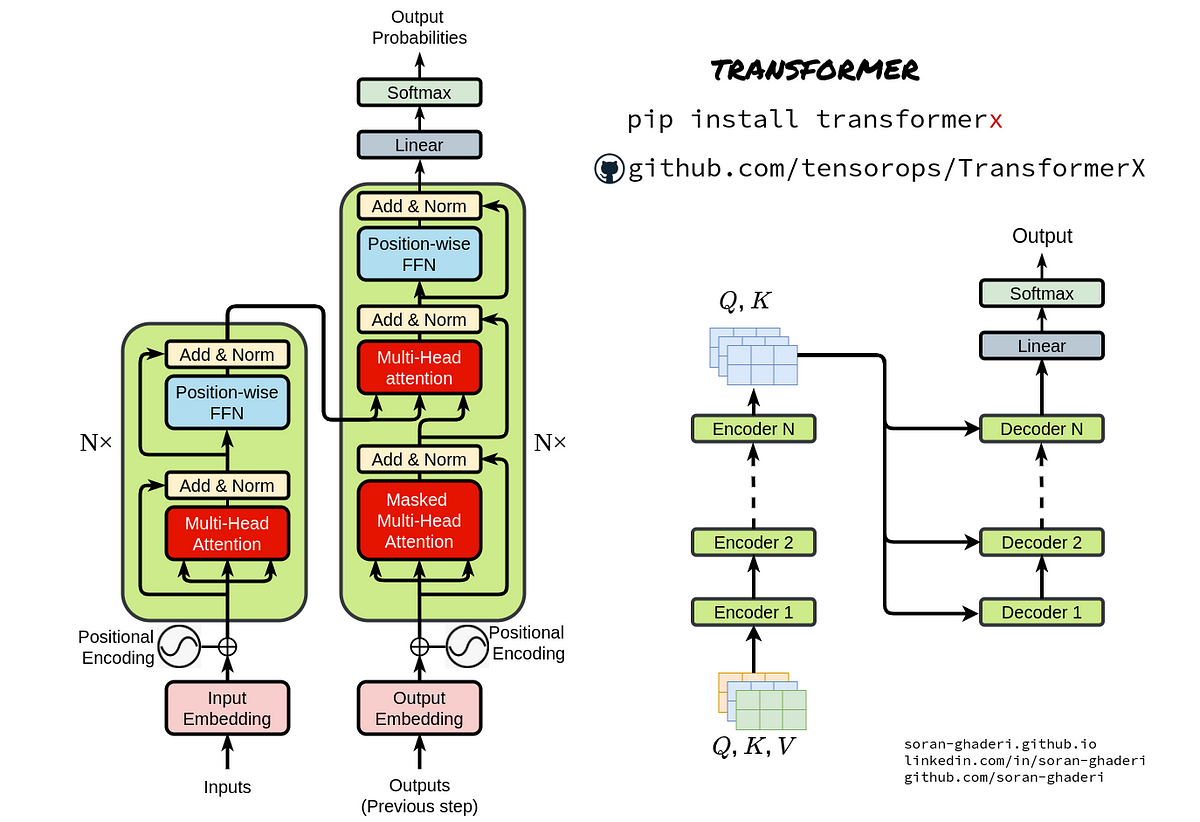
셀프-어텐션 메커니즘 소개
셀프-어텐션 메커니즘은 트랜스포머 모델의 핵심적인 요소로, 이를 통해 모델은 입력된 문장의 각 단어에 대한 중요도를 동적으로 조절하며, 전체 문장의 맥락을 고려합니다.
셀프-어텐션 메커니즘은 크게 세 가지 단계로 이루어집니다. 첫째, 각 단어에 대해 '키(Key)', '값(Value)', '쿼리(Query)'라는 세 가지 벡터를 생성합니다. 둘째, 쿼리 벡터와 모든 키 벡터간의 유사도를 계산하여 어텐션 스코어(Attention Score)를 얻습니다. 이 스코어는 문장의 각 단어가 주어진 단어에 얼마나 중요한지를 나타냅니다. 셋째, 이 스코어를 값 벡터에 적용하여 가중합을 구합니다. 이 과정을 통해 얻은 출력 벡터는 입력 문장의 맥락을 반영한 결과입니다.
이러한 셀프-어텐션 메커니즘 덕분에 트랜스포머 모델은 문장의 각 단어를 독립적으로 처리하는 것이 아니라, 그들 사이의 관계를 고려하여 더욱 풍부한 문맥 이해를 가능하게 합니다. 이는 특히 기계 번역, 요약 등의 작업에서 중요한 역할을 합니다. 단어의 순서가 문맥 이해에 결정적인 영향을 미치는 언어들, 예를 들어 한국어와 같은 언어를 처리하는 데에 있어서 특히 유용합니다.
셀프-어텐션 메커니즘은 또한 모델의 병렬 처리 능력을 향상시킵니다. 기존의 순차적인 방식과 달리, 트랜스포머 모델은 문장의 모든 단어를 동시에 처리할 수 있습니다. 이로 인해 더 빠른 처리 속도와 더 긴 문장의 효과적인 처리를 가능하게 합니다.
요약하자면, 셀프-어텐션 메커니즘이 트랜스포머 모델에 깊은 문맥 이해, 빠른 처리 속도, 그리고 더 긴 문장 처리 능력 등의 강점을 제공합니다. 이는 트랜스포머 모델이 다양한 NLP 작업에 있어 우수한 성능을 발휘하는 핵심적인 요인입니다.
https://youtu.be/RSSVWpBak6s
셀프-어텐션 메커니즘의 장점
셀프-어텐션 메커니즘이 주는 장점은 크게 두 가지로, 빠른 처리 속도와 더 긴 문장의 효과적인 처리입니다.
1. 빠른 처리 속도: 트랜스포머 모델이 셀프-어텐션 메커니즘을 이용하면, 문장의 모든 단어를 동시에 처리할 수 있습니다. 이는 병렬 처리를 가능하게 하여 처리 속도를 향상시킵니다. 실제로, 이는 기계 번역 등의 분야에서 매우 중요한 이점으로 작용합니다. 예를 들어, Google은 자체 번역 서비스인 Google Translate에서 트랜스포머 모델을 사용하고 있습니다. 이를 통해 Google Translate는 수백만 명의 사용자로부터 오는 요청을 빠르게 처리할 수 있습니다.
2. 더 긴 문장의 효과적인 처리: 셀프-어텐션 메커니즘은 모델이 문장의 각 단어를 다른 모든 단어와의 관계 맥락에서 이해하도록 합니다. 이는 모델이 더 긴 문장을 처리하면서도 문맥을 유지할 수 있게 해줍니다. 이는 특히 문서 요약이나 문장 생성과 같은 작업에서 유용합니다. 실제로, OpenAI의 GPT-3와 같은 대형 언어 모델들은 트랜스포머의 셀프-어텐션 메커니즘을 활용해 더욱 긴 문장을 효과적으로 처리하며, 이를 통해 풍부한 문맥 이해와 함께 더욱 자연스럽고 의미 있는 문장 생성을 가능하게 하고 있습니다.
셀프-어텐션 메커니즘은 이처럼 빠른 처리 속도와 더 긴 문장의 효과적인 처리 능력을 제공함으로써, 다양한 NLP 작업에 있어 트랜스포머 모델의 성능을 크게 향상시킵니다. 다음 섹션에서는 이러한 이점들을 어떻게 실제 문제 해결에 활용할 수 있는지 살펴보겠습니다.
https://www.geeky-gadgets.com/chatgpt-terms-explained/
100 ChatGPT terms explained from NLP to Entity Extraction
If you are looking to learn more about ChatGPT or AI models in general this list of 100 ChatGPT terms and their meanings might help you under
www.geeky-gadgets.com
자연어 처리(NLP) 분야는 트랜스포머 모델과 그 핵심 메커니즘인 셀프-어텐션 덕분에 지금껏 볼 수 없던 진보를 이루어냈습니다. 이들은 기계 번역에서 감성 분석, 요약, 챗봇 구현에 이르기까지 다양한 NLP 작업에 있어 우수한 성능을 제공하며, 빠른 처리 속도와 더 긴 문장의 효과적인 처리 능력을 보여줍니다.
특히 셀프-어텐션 메커니즘은 문장의 각 단어를 독립적으로 보지 않고 전체 문맥 안에서 이해하도록 하여, 더욱 깊고 정확한 문맥 이해를 가능하게 합니다. 이를 통해 트랜스포머 모델은 문장의 길이에 관계없이 문맥을 유지하며 빠르게 처리하는 능력을 갖췄습니다.
이러한 장점들은 트랜스포머 모델이 NLP 분야에서 가장 중요한 도구 중 하나로 자리매김하게 만들었습니다. 앞으로의 연구에서도 트랜스포머와 셀프-어텐션 메커니즘은 계속해서 중요한 역할을 하게 될 것입니다. 이들은 우리의 언어 이해 능력을 향상시키고, 더욱 다양한 문제를 효과적으로 해결할 수 있는 방법을 제공할 것입니다.
향후 NLP 분야에서는 트랜스포머의 성능을 더욱 향상시킬 새로운 메커니즘 및 모델 개발, 그리고 이를 다양한 어플리케이션에 적용하는 연구가 진행될 것으로 보입니다. 이런 흐름 속에서 트랜스포머 모델은 계속해서 자연어 처리의 중심에 서 있을 것이며, 셀프-어텐션 메커니즘은 그 핵심적인 요소로 작용할 것입니다.